

INTRODUCTION
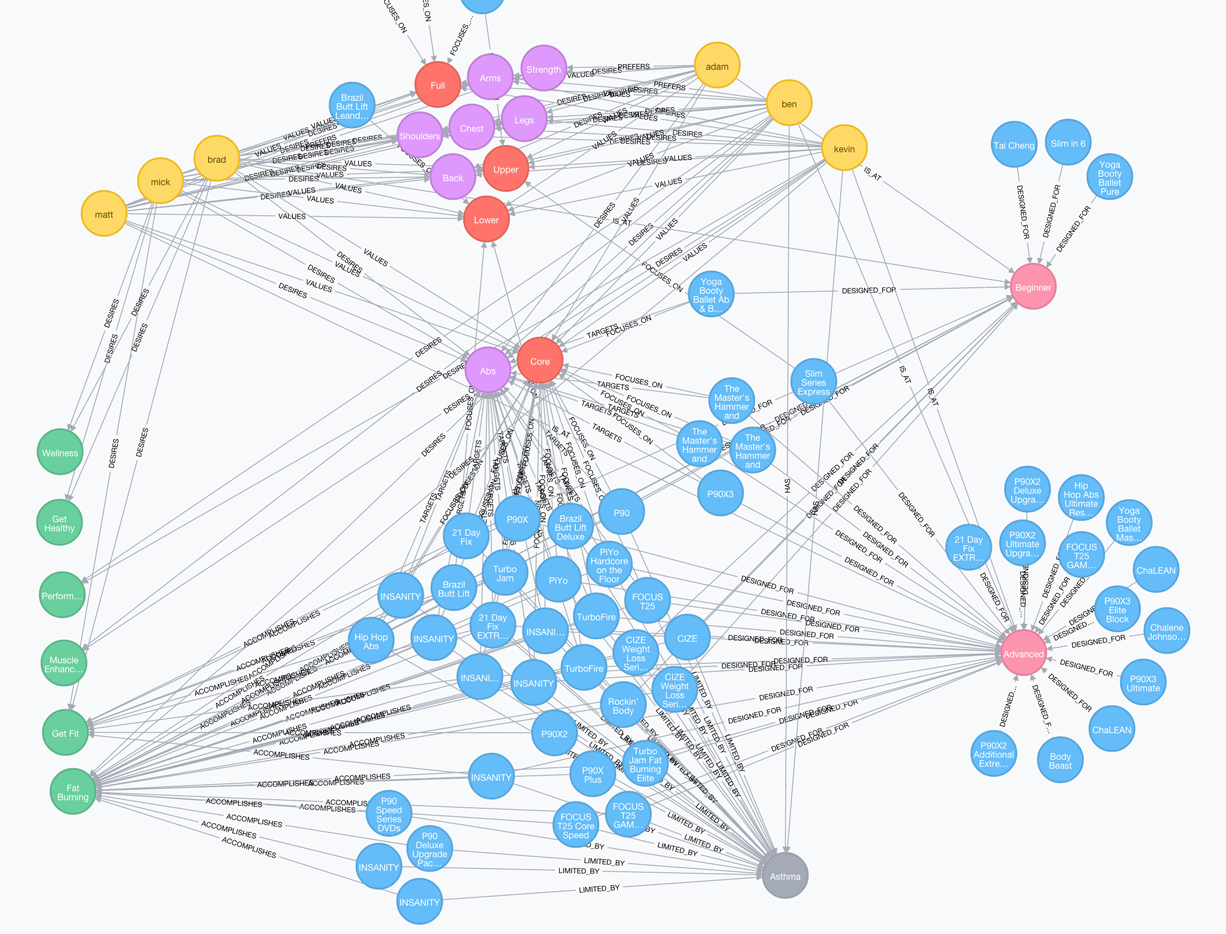
Neo4j is a highly popular, open-source graph database management system. It is built on the principles of graph theory and allows users to model and query complex relationships between data in a highly intuitive and efficient manner.
One of the key advantages of Neo4j is its ability to handle large amounts of data and relationships with ease. The graph data model allows for flexible and efficient querying of data, making it a great choice for applications that involve data with many connections and dependencies. Additionally, Neo4j's Cypher query language is designed to be highly readable and easy to use, making it accessible to developers of all skill levels.
Another major advantage of Neo4j is its scalability. The database can handle millions of nodes and relationships, and can be easily scaled up or down to meet the needs of any application. Additionally, Neo4j's built-in cluster support allows for easy horizontal scaling, making it a great option for organizations that need to handle large amounts of data.
Neo4j also has a rich ecosystem of tools and libraries to support developers. These include libraries for popular programming languages like Java, Python, and JavaScript, as well as visualization tools and other plugins to help developers work with the data stored in Neo4j.
One use case of Neo4j is its use in recommendation systems. It can be used to store and query data on users, items, and their interactions, and then use that data to make personalized recommendations to users. Additionally, Neo4j can be used in fraud detection and network analysis, as it can easily store and query data on connections between entities.
Overall, Neo4j is a powerful and versatile graph database management system that is well-suited to a wide range of use cases. Its ability to handle large amounts of data and relationships, along with its intuitive and easy-to-use query language, make it a great choice for developers looking to build applications that involve complex data. Additionally, its scalability and rich ecosystem of tools and libraries make it a great option for organizations that need to handle large amounts of data.
ARCHITECTURE
Neo4j's architecture is based on a master-slave model, where one server acts as the master and the other servers act as slaves. The master server is responsible for handling all write operations, while the slaves handle all read operations. This allows for highly efficient and scalable operation, as the read and write operations can be handled by different servers, allowing for better utilization of resources.
The data in Neo4j is stored in a format called Property Graph. A property graph is a mathematical graph, where the nodes represent entities and the edges represent the relationships between them. Each node and edge has a set of properties, which are key-value pairs that provide additional information about the nodes and edges.
The nodes and edges in Neo4j are stored in a highly optimized data structure called a native store. This allows for fast and efficient storage and retrieval of data, and also enables Cypher, Neo4j's query language, to perform complex queries on the data with high performance. Additionally, Neo4j also support indexing and querying of the data to optimize the performance of the querying.
In summary, Neo4j's architecture is based on a master-slave model, which allows for highly efficient and scalable operation. The data is stored in the property graph format, which consists of nodes, edges and properties, and it is optimized for fast and efficient storage and retrieval of data. Additionally, the native store and querying capabilities allow for complex queries on the data with high performance.
SOME USECASES AND EXAMPLES
Cypher is the query language used in Neo4j to query and manipulate the data stored in the graph. Here are some examples of Cypher syntax and code:
- Creating nodes and relationships:
CREATE (:Person { name: "John", age: 30 }) CREATE (:Person { name: "Jane", age: 25 }) CREATE (:Person { name: "Bob", age: 35 }) CREATE (j:Person { name: "John", age: 30 })-[:KNOWS]->(b:Person { name: "Bob", age: 35 })In this example, we're creating three nodes with the label "Person" and properties "name" and "age". Then we're creating a relationship of type "KNOWS" between the nodes "John" and "Bob".
Retrieving data:
MATCH (p:Person) RETURN pThis query retrieves all the nodes with the label "Person" and returns the nodes.
Updating data:
MATCH (p:Person { name: "John" }) SET p.age = 32This query matches the node with the label "Person" and the property "name" equal to "John" and sets the "age" property to 32
Deleting data:
MATCH (p:Person { name: "John" }) DELETE pThis query matches the node with the label "Person" and the property "name" equal to "John" and deletes the node.
Filtering data:
MATCH (p:Person) WHERE p.age > 30 RETURN pThis query matches all the nodes with the label "Person" and filters the results to only return nodes where the "age" property is greater than 30.
These are just a few examples of Cypher syntax and code. Cypher is a very powerful and flexible language, and it can be used to express a wide range of queries and manipulations on the data stored in Neo4j. Additionally, Cypher supports indexing and querying, which can be used to optimize the performance of queries.

THE DEEPER THE BETTER
One of the key components of Neo4j's architecture is the storage layer. The storage layer is responsible for persisting the graph data and managing the relationships between nodes and edges. Neo4j uses a native storage format, called the native store, which is optimized for fast and efficient storage and retrieval of graph data. The native store uses a memory-mapped file system to store the data on disk, which allows for fast access to the data, even when working with very large datasets.
Another important component of Neo4j's architecture is the query layer. The query layer is responsible for processing Cypher queries, Neo4j's query language, and providing the results to the application. Cypher is designed to be highly readable and easy to use, and it allows developers to express complex queries in a natural and intuitive way. Cypher also supports indexing and querying, to optimize the performance of the querying.
The Neo4j's architecture also has a caching layer, which is responsible for caching frequently accessed data in memory to improve query performance. The caching layer uses a Least Recently Used (LRU) algorithm to determine which data to cache and when to evict data from the cache. This caching layer can significantly improve query performance, particularly when working with large datasets.
In addition to the above, Neo4j also has a robust security model that allows for granular control over access to data. It has built-in support for authentication and authorization, and it allows for the creation of custom roles and permissions. This makes it suitable for use in a wide range of applications, including those with sensitive data.
Another important aspect of Neo4j is its scalability. Neo4j's architecture is designed to scale horizontally, which means that it can easily be scaled out by adding more servers to the cluster. This allows Neo4j to handle very large datasets and high query loads, making it suitable for use in high-traffic applications and big data scenarios.
In summary, Neo4j's architecture is designed to provide fast and efficient storage and retrieval of graph data, while also providing a robust and easy-to-use query language. The native storage format, caching layer, and query layer work together to provide high performance, even when working with very large datasets. Additionally, the architecture is designed to scale horizontally, making it suitable for use in high-traffic applications and big data scenarios, and the security model provides granular control over access to data.